Чтобы нужные страницы сайта попадали в индекс поисковых систем, важно правильно настроить файл robots.txt. Этот документ дает рекомендации поисковым роботам, какие страницы обрабатывать, а какие — нет: например, от индексации можно закрыть панель управления сайтом или страницы, которые находятся в разработке. Рассказываем, как правильно настроить robots.txt, если ваш сайт сделан на WordPress.
Что такое robots.txt и для чего он нужен?
Чтобы понять, какие страницы есть на сайте, поисковики «напускают» на него роботов: они сканируют сайт и передают перечень страниц в поисковую систему. robots.txt — это текстовый файл, в котором содержатся указания о том, какие страницы можно, а какие нельзя сканировать роботам.
Обычно на сайте есть страницы, которые не должны попадать в выдачу: например, это может быть административная панель, личные страницы пользователей или временные страницы сайта. Кроме этого, у поисковых роботов есть определенный лимит сканирования страниц (кроулинговый бюджет) — за раз они могут обработать только ограниченное их количество.
Проведем аналогию: представим сайт в виде города, а страницы в виде домов. По дорогам между домов ездят роботы и записывают информацию о каждом доме (индексируют страницы и добавляют в базу). Роботы получают ограниченное количество топлива в день — например, 10 литров на объезд города в день. Это топливо — кроулинговый бюджет, который выделяют поисковые системы на обработку сайта.
На маленьких проектах, 500-1000 страниц, кроулинговый бюджет не сказывается критично, но на интернет-магазинах, маркетплейсах, больших сервисах могут возникнут проблемы. Если они спроектированы неверно, то робот может месяцами ездить по одному кварталу (сканировать одни и те же страницы), но не заезжать в отдаленные районы. Чем больше проект, тем больший кроулинговый бюджет выделяют поисковики, но это не поможет, если дороги сделаны неудобно и вместо прямой дороги в 1 км нужно делать крюк в 15 км.
Правильный robots.txt помогает решить часть этих проблем.
Разные поисковые системы по-разному обрабатывают robots.txt: например, Google может включить в индекс даже ту страницу, которая запрещена в этом файле, если найдет ссылку на такую страницу на страницах сайта. Яндекс же относится к robots.txt как к руководству к действию — если страница запрещена для индексации в файле, она не будет включена в результаты поиска, но с момента запрета может пройти до двух недель до исключения из индекса. Таким образом, правильная настройка robots.txt в 99% случаев помогает сделать так, чтобы в индекс попадали только те страницы, которые вы хотите видеть в результатах поиска.
Кроме этого, robots.txt может содержать технические сведения о сайте: например, главное зеркало, местоположение sitemap.xml или параметры URL-адресов, передача которых не влияет на содержимое страницы.
Файл robots.txt рекомендует роботам поисковых систем, как правильно обрабатывать страницы сайта, чтобы они попали в выдачу.
Где находится файл robots.txt?
По умолчанию в WordPress нет файла robots.txt. При установке WordPress создает виртуальный файл robots.txt с таким содержимым:
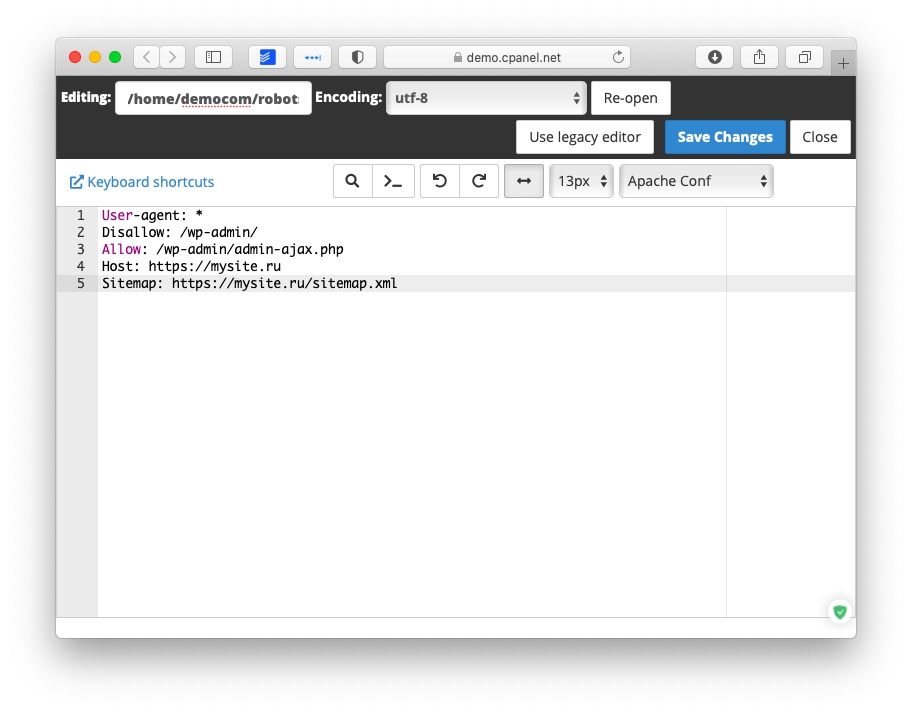
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpТакая настройка говорит поисковым роботам следующее:
User-agent: * — для любых поисковых роботов
Disallow: /wp-admin/ — запретить обрабатывать /wp-admin/
Allow: /wp-admin/admin-ajax.php — разрешить обрабатывать элементы сайта, которые загружаются через AJAX
Этот файл не получится найти в папках WordPress — он работает, но физически его не существует. Поэтому, чтобы настроить robots.txt, сначала нужно его создать.
Robots.txt должен находиться в корневой папке (mysite.ru/robots.txt), чтобы роботы любых поисковых систем могли его найти.
Как редактировать и загружать robots.txt
Есть несколько способов создать файл robots.txt — либо сделать его вручную в текстовом редакторе и разместить в корневом каталоге (папка самого верхнего уровня на сервере), либо воспользоваться специальными плагинами для настройки файла.
Как создать robots.txt в Блокноте
Самый простой способ создать файл robots.txt — написать его в блокноте и загрузить на сервер в корневой каталог.
Лучше не использовать стандартное приложение — воспользуйтесь специальными редакторы текста, например, Notepad++ или Sublime Text, которые поддерживают сохранение файла в конкретной кодировке. Дело в том, что поисковые роботы, например, Яндекс и Google, читают только файлы в UTF-8 с определенными переносами строк — стандартный Блокнот Windows может добавлять ненужные символы или использовать неподдерживаемые переносы.
Говорят, что это давно не так, но чтобы быть уверенным на 100%, используйте специализированные приложения.
Рассмотрим создание robots.txt на примере Sublime Text. Откройте редактор и создайте новый файл. Внесите туда нужные настройки, например:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://mysite.ru/sitemap.xmlГде mysite.ru — домен вашего сайта.
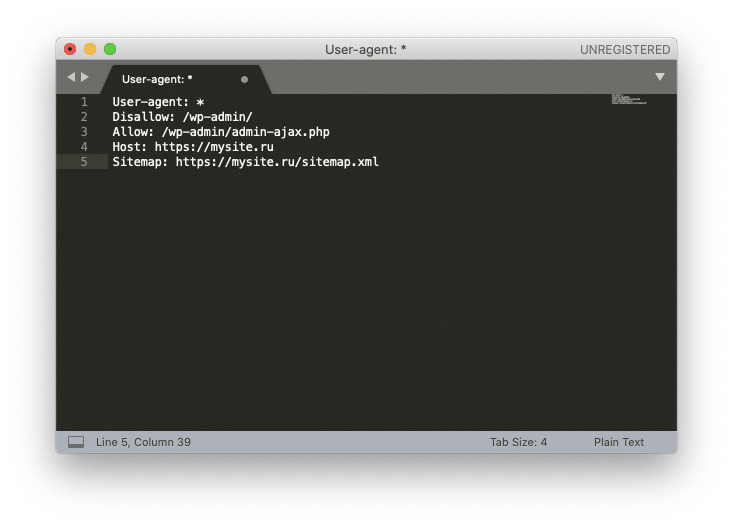
После того, как вы записали настройки, выберите в меню File ⟶ Save with Encoding… ⟶ UTF-8 (или Файл ⟶ Сохранить с кодировкой… ⟶ UTF-8).
Назовите файл “robots.txt” (обязательно с маленькой буквы).
Файл готов к загрузке.
Загрузить robots.txt через FTP
Для того, чтобы загрузить созданный robots.txt на сервер через FTP, нужно для начала включить доступ через FTP в настройках хостинга.
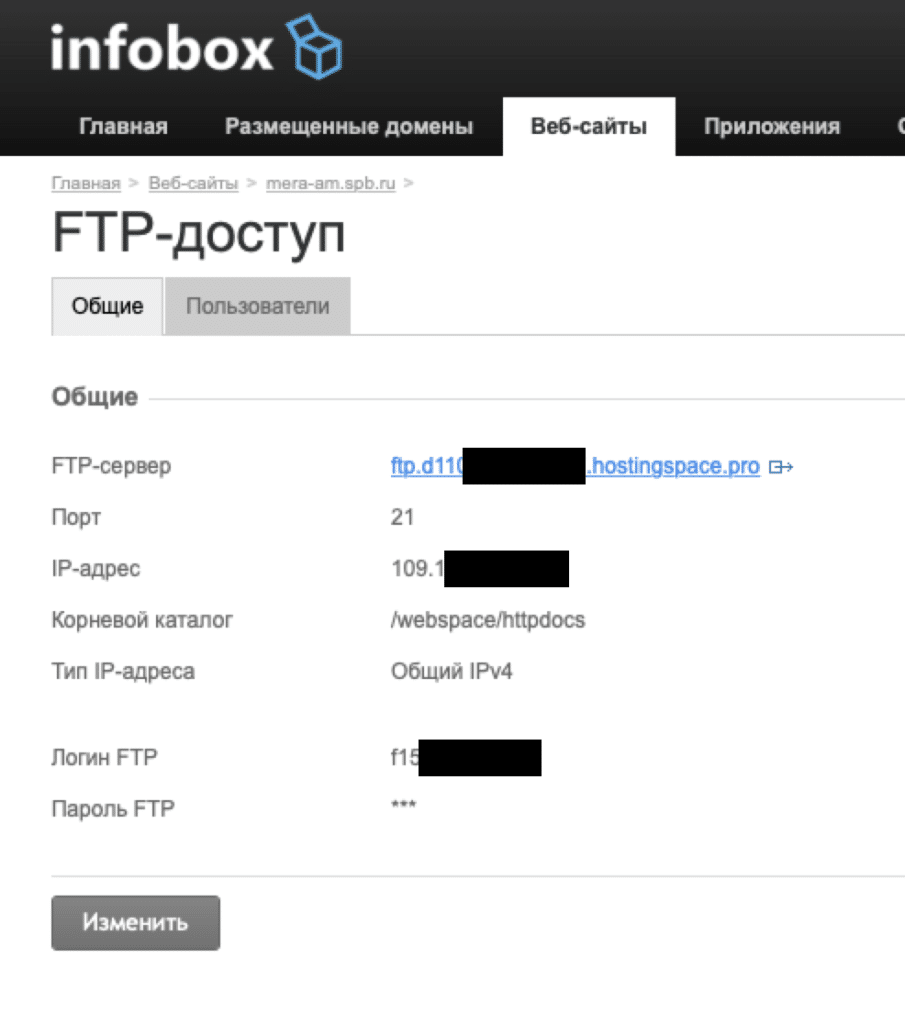
После этого скопируйте настройки доступа по FTP: сервер, порт, IP-адрес, логин и пароль (не совпадают с логином и паролем для доступа на хостинг, будьте внимательны!).
Чтобы загрузить файл robots.txt вы можете воспользоваться специальным файловым менеджером, например, FileZilla или WinSCP, или же сделать это просто в стандартном Проводнике Windows. Введите в поле поиска “ftp://адрес_FTP_сервера”.
После этого Проводник попросит вас ввести логин и пароль.
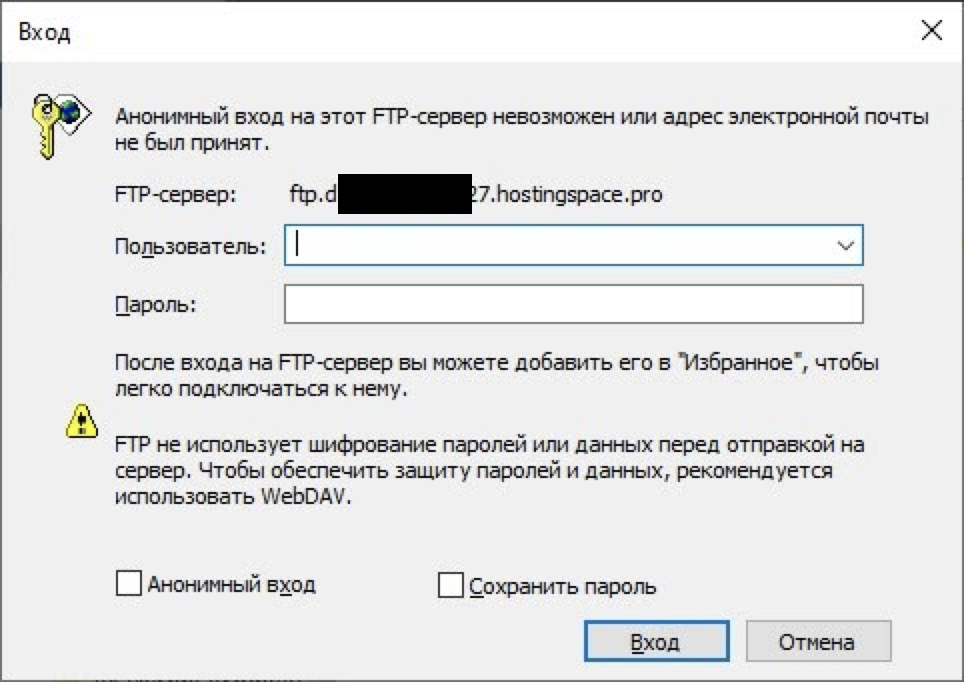
Введите данные, которые вы получили от хостинг-провайдера на странице настроек доступа FTP. После этого в Проводнике откроются файлы и папки, расположенные на сервере. Скопируйте файл robots.txt в корневую папку. Готово.
Загрузить или создать robots.txt на хостинге
Если у вас уже есть готовый файл robots.txt, вы можете просто загрузить его на хостинг. Зайдите в файловый менеджер панели управления вашим хостингом, нажмите на кнопку «Загрузить» и следуйте инструкциям (подробности можно узнать в поддержке у вашего хостера.
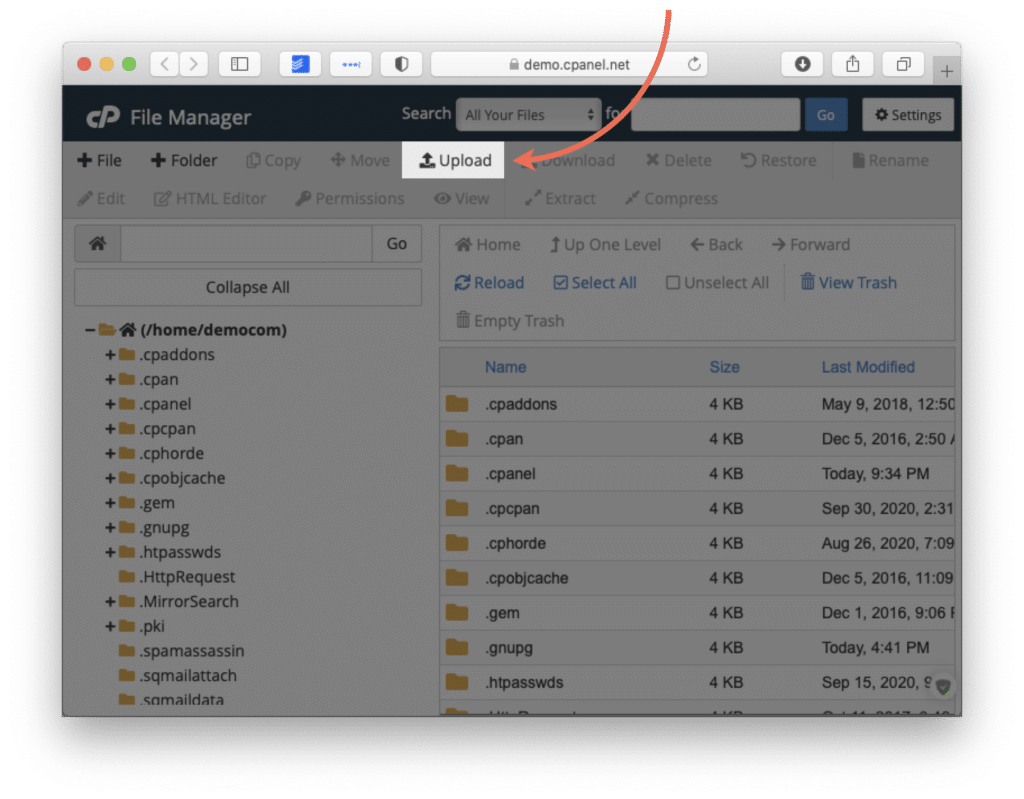
Многие хостинги позволяют создавать текстовые файлы прямо в панели управления хостингом. Для этого нажмите на кнопку «Создать файл» и назовите его “robots.txt” (с маленькой буквы).
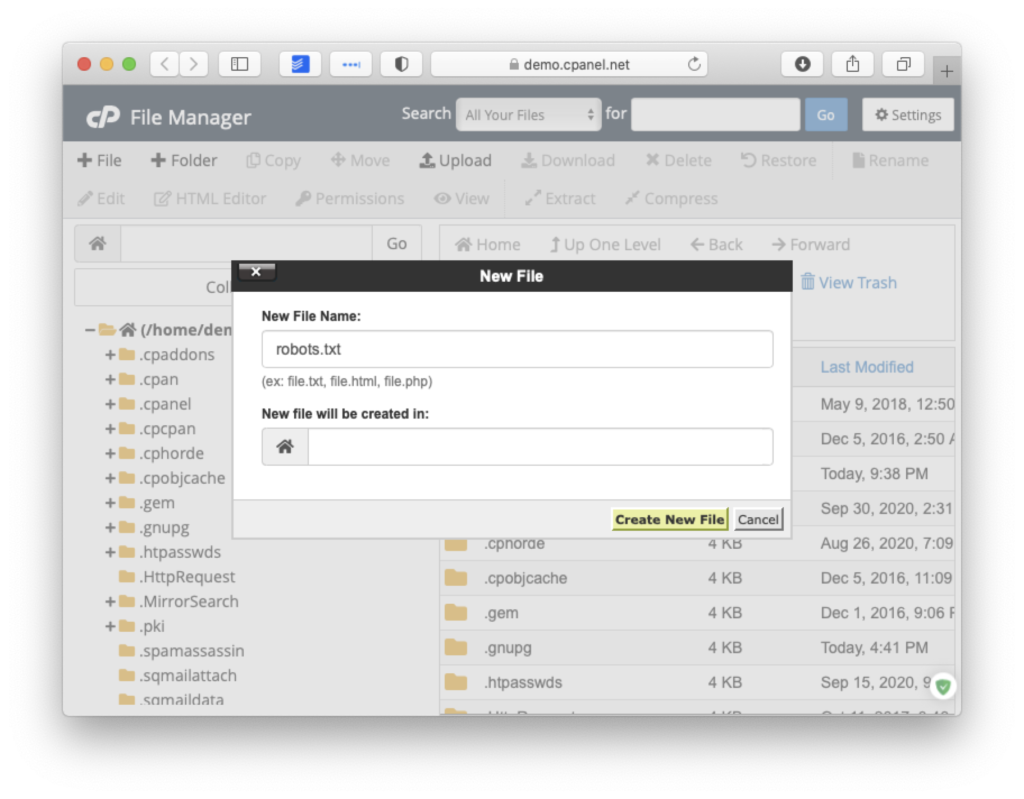
После этого откройте его во встроенном текстовом редакторе хостера. Если вам предложит выбрать кодировку для открытия файла — выбирайте UTF-8.
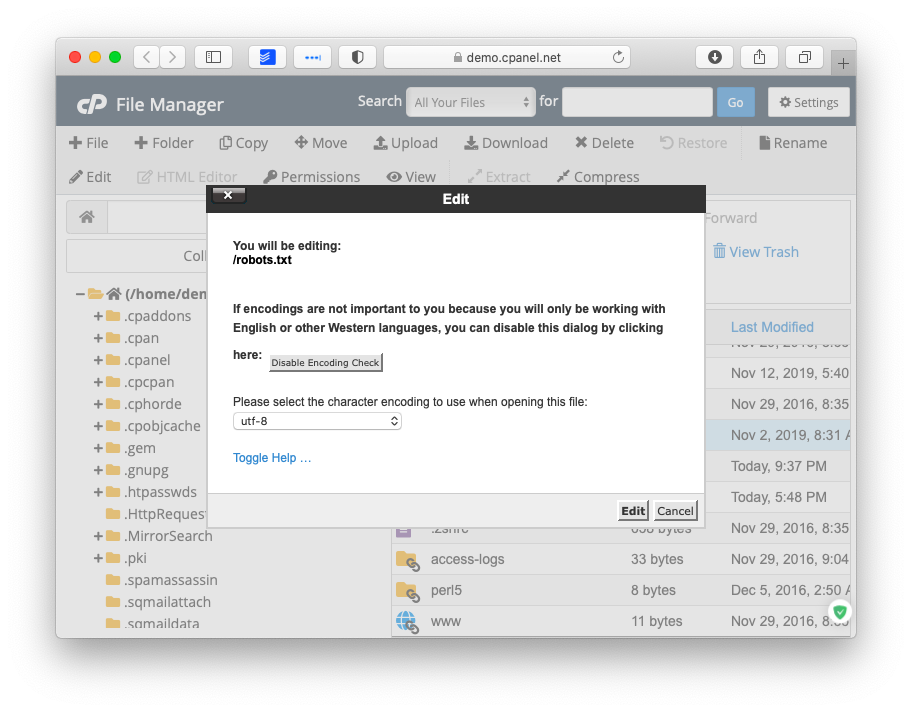
Добавьте нужные директивы и сохраните изменения.
Плагины для редактирования robots.txt
Гораздо проще внести нужные директивы в robots.txt с помощью специальных плагинов для редактирования прямо из панели управления WordPress. Самые популярные из них — ClearfyPro, Yoast SEO и All in One SEO Pack.
Clearfy Pro
Этот плагин отлично подходит для начинающих: даже если вы ничего не понимаете в SEO, Clearfy сам создаст правильный и валидный файл robots.txt. Кроме этого, плагин предлагает пошаговую настройку самых важных для поисковой оптимизации функций, так что на первых этапах развития сайта этого будет достаточно.
Чтобы настроить robots.txt, в панели управления WordPress перейдите в пункт Настройки ⟶ Clearfy ⟶ SEO.
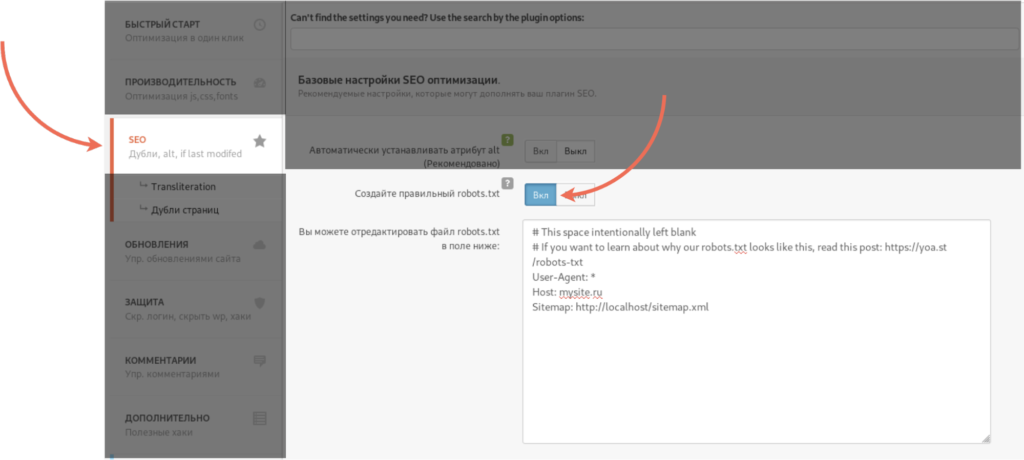
Переключите «Создайте правильный robots.txt» в положение «Вкл». Clearfy отобразит правильные настройки файла robots.txt. Вы можете дополнить эти настройки, например, запретив поисковым роботам индексировать папку /wp-admin/.
После внесения настроек нажмите на кнопку «Сохранить» в верхнем правом углу.
Yoast SEO
Плагин Yoast SEO хорош тем, что в нем есть много настроек для поисковой оптимизации: он напоминает использовать ключевые слова на странице, помогает настроить шаблоны мета-тегов и предлагает использовать мета-теги Open Graph для социальных сетей.
С его помощью можно отредактировать и robots.txt.
Для этого зайдите в раздел Yoast SEO ⟶ Инструменты ⟶ Редактор файлов.
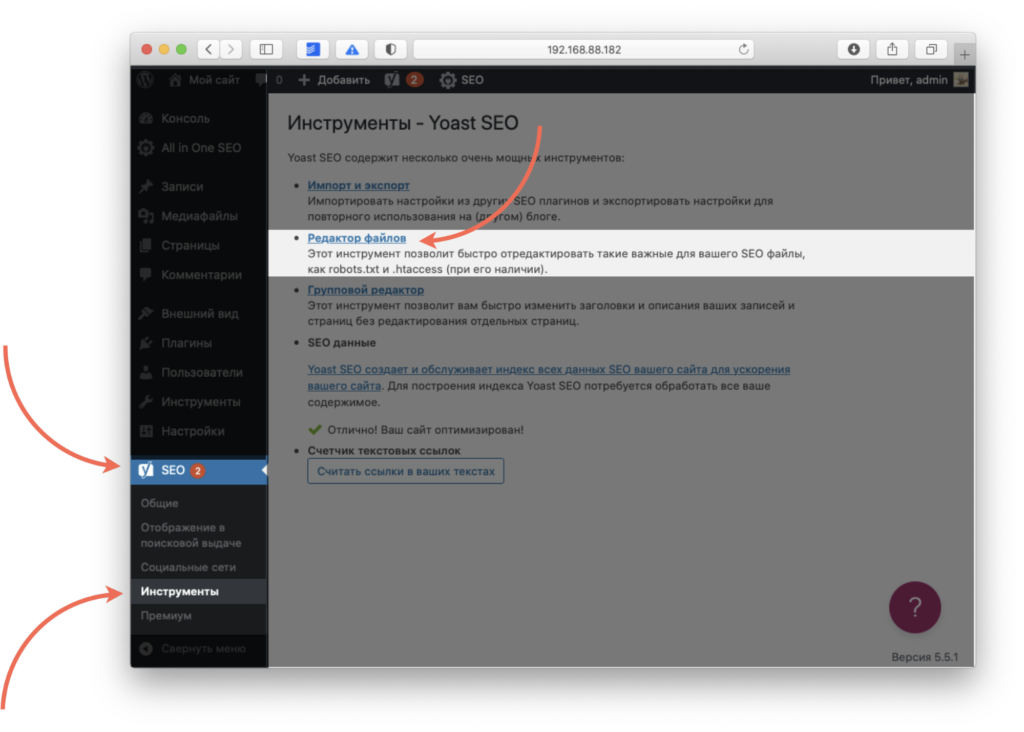
Здесь вы сможете отредактировать robots.txt и сохранить его, не заходя на хостинг. По умолчанию Yoast SEO не предлагает никаких настроек для файла, так что его придется прописать вручную.
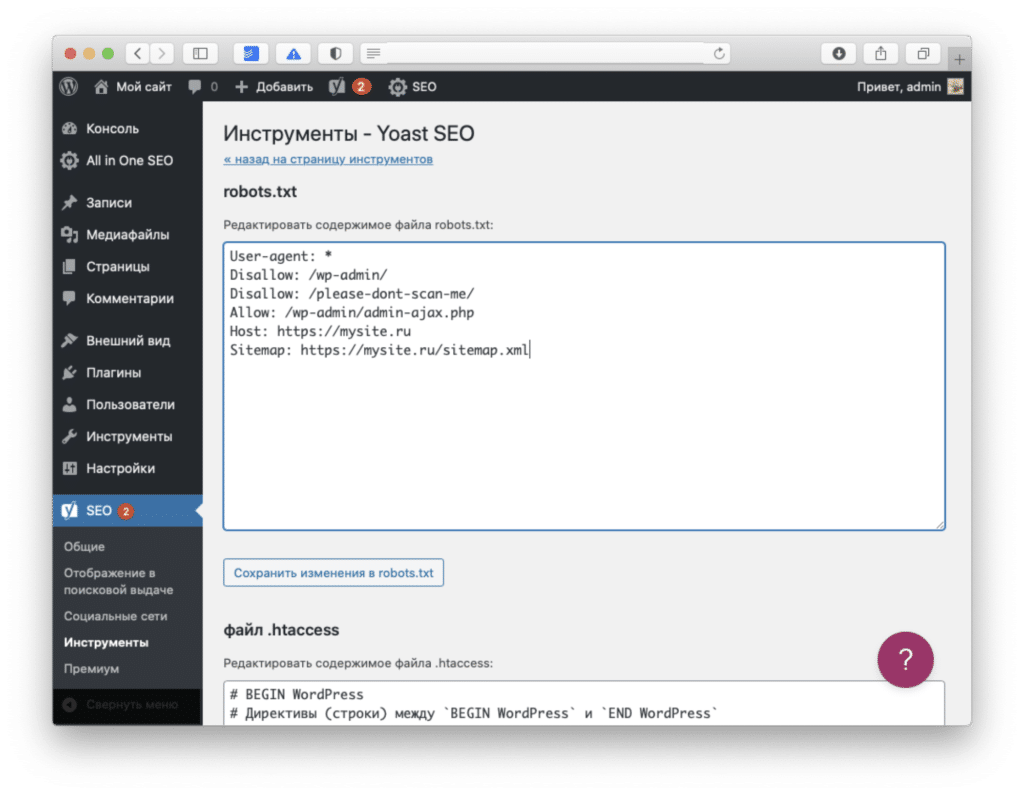
После изменений нажмите на кнопку «Сохранить изменения в robots.txt».
All in One SEO Pack
Еще один мощный плагин для управления SEO на WordPress. Чтобы отредактировать robots.txt через All in One SEO Pack, сначала придется активировать специальный модуль. Для этого перейдите на страницу плагина в раздел «Модули» и нажмите «Активировать» на модуле «robots.txt».
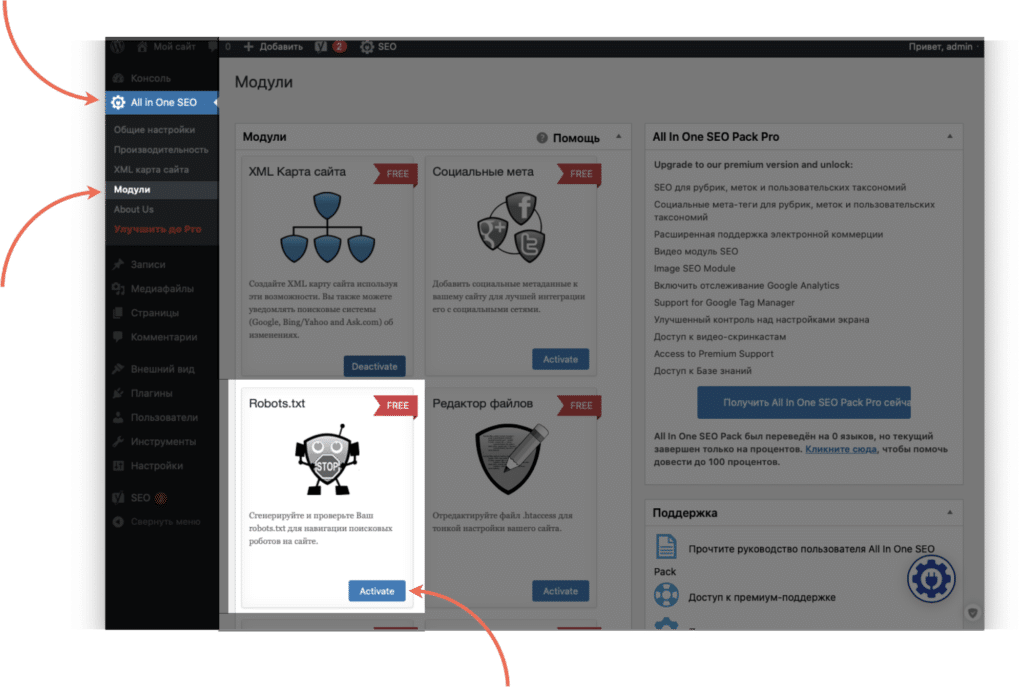
После подключения модуля перейдите на его страницу. С помощью него можно разрешать или запрещать для обработки конкретные страницы и группы страниц для разных поисковых роботов, не прописывая директивы вручную.
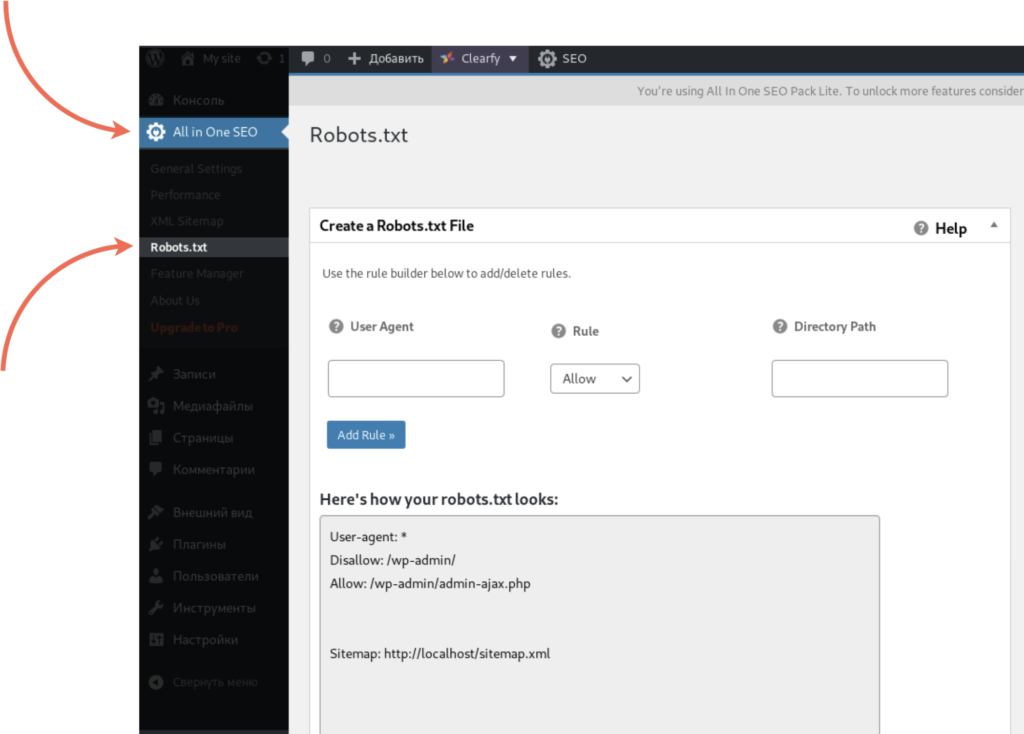
Правильный и актуальный robots.txt в 2020 году
Для того, чтобы создать правильный файл robots.txt, нужно знать, что означает каждая из директив в файле, записать их в правильном порядке и проверить файл на валидность.
Что означают указания в файле robots.txt?
User-agent — поисковой робот
В строке User-agent указывается, для каких роботов написаны следующие за этой строкой указания. Например, если вы хотите запретить индексацию сайта для поисковых роботов Bing, но разрешить для Google и Яндекс, это будет выглядеть примерно так:
| User-agent: Googlebot Disallow: User-agent: Yandex User-agent: Bingbot |
Для робота Google Запретить: ничего Для робота Яндекс Для робота Bing |
На практике необходимость разграничивать указания для разных поисковых роботов встречается довольно редко. Гораздо чаще robots.txt пишут для всех роботов сразу. Это указывается через звездочку:
User-agent: *У поисковых систем есть и специальные роботы — например, бот YandexImages обходит изображения, чтобы выдавать их в поиске Яндекса по картинкам, а Googlebot-News собирает информацию для выдаче в Google Новостях. Полные списки ботов можно найти в справке поисковых систем — введите в поиск «поисковые роботы [название ПС]».
Disallow
Эта директива сообщает поисковым роботам, что страница или целый список страниц запрещены для обхода. Важно понимать, что указание в robots.txt не гарантирует, что страница не попадет в выдачу — если ссылка на запрещенную в файле страницу встречается на разрешенных страницах сайта, поисковик все равно может включить его в индекс.
Если вы хотите разрешить поисковым роботам обрабатывать все страницы сайта, оставьте это указание пустым.
User-agent: *
Disallow:Если вам нужно запретить для индексации несколько страниц или директорий, указывайте каждую из них отдельно:
User-agent: *
Disallow: /wp-admin/
Disallow: /dev/
Disallow: /index2.htmlAllow
Это указание разрешает ботам поисковиков сканировать определенные страницы. Обычно это используют, когда нужно закрыть целую директорию, но разрешить обрабатывать часть страниц.
User-agent: *
Disallow: /wp-admin/
Disallow: /dev/
Allow: /dev/index.phpБольшинство поисковых систем обрабатывают в первую очередь более точные правила (например, с указанием конкретных страниц), а затем — более широкие. Например:
User-agent: *
Disallow: /wp-admin/
Disallow: /dev/
Allow: /dev/index.phpТакой файл robots.txt укажет роботам, что не нужно сканировать все страницы из папки «catalog», кроме «best-offers.html».
Host
Указание host говорит поисковым роботам, какое из зеркал сайта является главным. Например, если сайт работает через защищенный протокол https, в robots.txt стоит это указать:
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ruЭта директива уже устарела, и сегодня ее использовать не нужно. Если она есть в вашем файле сейчас, лучше ее удалить — есть мнение, что она может негативно сказываться на продвижении.
Sitemap
Этот атрибут — еще один способ указать поисковым роботам, где находится карта сайта. Она нужна для того, чтобы поисковик смог добраться до любой страницы сайта в один клик вне зависимости от сложности его структуры.
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ru
Sitemap: https://mysite.ru/sitemap.xmlCrawl-delay
Такой параметр помогает установить задержку для обработки сайта поисковыми роботами. Это может быть полезно, если сайт расположен на слабом сервере и вы не хотите, чтобы боты перегружали его запросами: передайте в crawl-delay время, которое должно проходить между запросами роботов. Время передается в секундах.
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ru
Sitemap: https://mysite.ru/sitemap.xml
Crawl-delay: 10На самом деле современные поисковые роботы и так делают небольшую задержку между запросами, так что прописывать это явно стоит только в том случае, если сервер очень слабый.
Clean-param
Эта настройка пригодится, чтобы скрыть из поиска страницы, в адресе которых есть параметры, не влияющие на ее содержание. Звучит сложно, так что объясняем на примере.
Допустим, на сайте есть категория «Смартфоны» и она расположена по адресу mysite.ru/catalog/smartphones.
У категории есть фильтры, которые передаются с помощью GET-запроса. Предположим, пользователь отметил в фильтре «Производитель: Apple, Samsung». Адрес страницы поменялся на
mysite.ru/catalog/smartphones/?manufacturer=apple&manufacturer=samsung,
где ?manufacturer=apple&manufacturer=samsung — параметры, которые влияют на содержимое страницы. Логично, что такие страницы можно и нужно выводить в поиске — эту страницу со включенным фильтром можно продвигать по запросу вроде «смартфоны эппл и самсунг».
А теперь представим, что пользователь перешел в категорию «Смартфоны» по ссылке, которую вы оставили во ВКонтакте, добавив к ней UTM-метки, чтобы отследить, эффективно ли работает ваша группа.
mysite.ru/catalog/smartphones/?utm_source=vk&utm_medium=post&utm_campaign=sale
В такой ссылке параметры ?utm_source=vk&utm_medium=post&utm_campaign=sale не влияют на содержимое страницы — mysite.ru/catalog/smartphones/ и mysite.ru/catalog/smartphones/?utm_source=vk&utm_medium=post&utm_campaign=sale будут выглядеть одинаково.
Чтобы помочь поисковым роботам понять, на основании каких параметров содержимое меняется, а какие не влияют на контент страницы, и используется настройка Clean-param.
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ru
Sitemap: https://mysite.ru/sitemap.xml
Clean-param: utm_campaign /
Clean-param: utm_medium /
Clean-param: utm_source /С помощью такой директивы вы укажете поисковым роботам, что при обработке страниц для поисковой выдачи нужно удалять из ссылок такие параметры, как utm_campaign, utm_medium и utm_source.
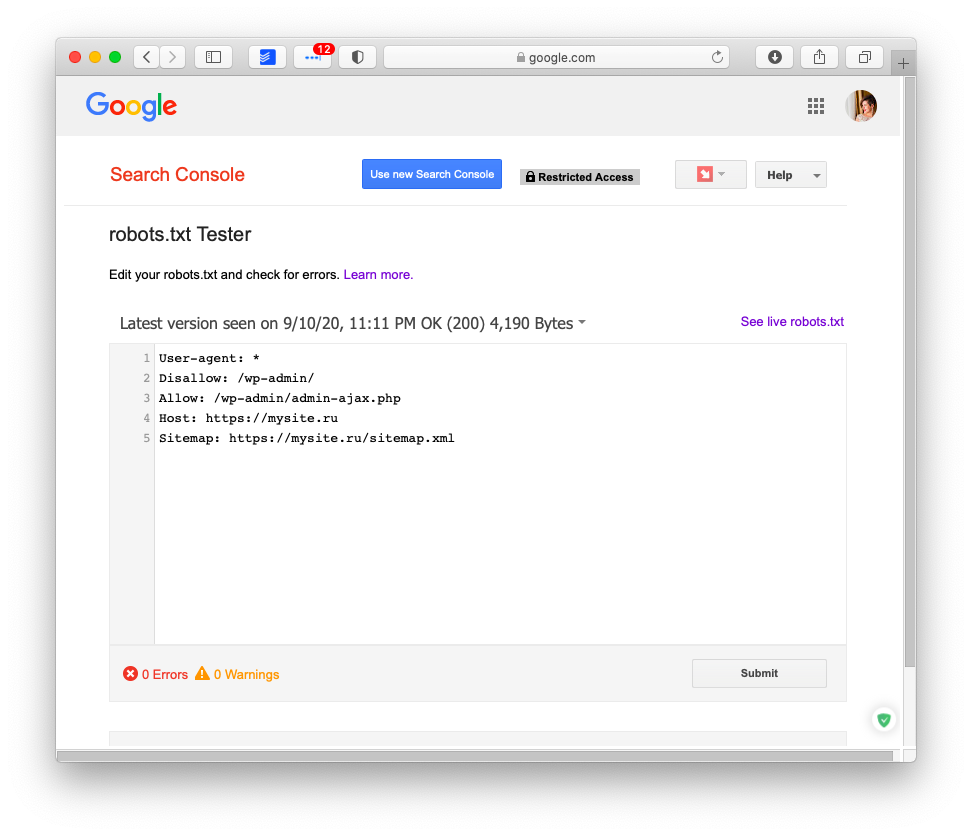
Как проверить robots.txt
Для того, чтобы проверить валидность robots.txt, можно использовать инструменты вебмастера поисковых систем. Инструмент проверки robots.txt есть у Google в Search Console — для его использования понадобится авторизация в Google и подтверждение прав на сайт, для которого проверяется файл.
Похожий инструмент для проверки robots.txt есть и у Яндекса, и он даже удобнее, потому что не требует авторизации.
Эти приложения помогают понять, как поисковый робот видит файл: если какие-то из директив прописаны в нем неверно, инструмент проверки их проигнорирует либо предупредит о них.
Чего стоит избегать при настройке robots.txt?
Будьте внимательны: хоть robots.txt непосредственно и не влияет на то, окажется ли ваш сайт в выдаче, этот файл помогает избежать попадания в индекс тех страниц, которые должны быть скрыты от пользователей. Все, что робот не сможет интерпретировать, он проигнорирует.
Вот несколько частых ошибок, которые можно допустить при настройке.
Не указан User-Agent
Или указан после директивы, например:
Disallow: /wp-admin/
User-agent: *Такую директиву робот прочитает так:
Disallow: /wp-admin/ — так, это не мне, не читаю
User-agent: * — а это мне… Дальше ничего? Отлично, обработаю все страницы!
Любые указания к поисковым роботам должны начинаться с директивы User-agent: название_бота.
User-agent: GoogleBot
Disallow: /wp-admin/
User-agent: Yandex
Disallow: /wp-admin/Или для всех сразу:
User-agent: *
Disallow: /wp-admin/Несколько папок в Disallow
Если вы укажете в директиве Disallow сразу несколько директорий, неизвестно, как робот это прочтет.
User-agent: *
Disallow: /wp-admin/ /catalog/ /temp/ /user/ — “/wp-admin/catalog/temp/user/”? “/catalog/ /user”? “??????”?По своему разумению он может обработать такую конструкцию как угодно. Чтобы этого не случилось, каждую новую директиву начинайте с нового Disallow:
User-agent: *
Disallow: /wp-admin/
Disallow: /catalog/
Disallow: /temp/
Disallow: /user/Регистр в названии файла robots.txt
Поисковые роботы смогут прочитать только файл с названием “robots.txt”. “Robots.txt”, “ROBOTS.TXT” или “R0b0t.txt” они просто проигнорируют.
Резюме
- robots.txt — файл с рекомендациями, как обрабатывать страницы сайта, для поисковых роботов.
- В WordPress по умолчанию нет robots.txt, но есть виртуальный файл, который запрещает ботам сканировать страницы панели управления.
- Создать robots.txt можно в блокноте и загрузить его на хостинг в корневой каталог.
- Файл robots.txt должен быть создан в кодировке UTF-8.
- Проще создать robots.txt с помощью плагинов для WordPress — Clearfy Pro, Yoast SEO, All in One SEO Pack или других SEO-плагинов.
- С помощью robots.txt можно создать директивы для разных поисковых роботов, сообщить о главном зеркале сайта, передать адрес sitemap.xml или указать параметры URL-адресов, которые не влияют на содержимое страницы.
- Проверить валидность robots.txt можно с помощью инструментов от Google и Яндекс.
- Все директивы файла robots.txt, которые робот не сможет интерпретировать, он проигнорирует.









А что значит User-agent? У Вас он только один и в виде звездочки, а в этой статье dampi(точка)ru/pravilnyiy-robots-txt-dlya-sayta-na-wordpress их куча и всяких разных
User-agent — инструкция, которая действительная только для определенного бота. Например, “Googlebot” для робота Google. Другие боты эту инструкцию будут игнорировать.